An introduction to mathematical modeling in systems biology GUI version
January 2023
v 8.2
Introduction
First thing to do, is to read the introductions "hidden" below.
Click to expand introduction
Purpose of the lab
This lab will on a conceptual level guide you through all the main sub-tasks in a systems biology project: model formulation, optimization of the model parameters with respect to experimental data, model evaluation, statistical testing, (uniqueness) analysis, identification of interesting predictions, and testing of those predictions.
How to pass
To pass the entire lab you need to pass the quiz called "Computer lab - GUI version" under the Quiz tab on the Lisam page. Along these instructions, there are check-points that correspond to questions in the quiz. These are marked with checkpoint x. Please feel free to talk to one of the supervisors if you have any questions regarding any of the checkpoints.
The deadline to be approved is at the final computer lab session
Preparations
Most of the tasks below start with read about .... If one wants to prepare, these can be read in advance of the lab. They are written more as a background about the different topics, and can be read without solving the previous tasks.
Getting MATLAB running
To do the lab, you need access to MATLAB. Depending on if you are using a private computer or one in the computer hall, you need to do either of the alteratives below.
On your own computer
If you don’t already have a Mathworks account, start by making one. If you are a student at Liu you have access to a MATLAB licens via the student portal on Lisam.
Go to the Mathworks homepage, download and install MATLAB (version R2018b, or later).
Note that when prompted during the installation, you’ll need to install the Global Optimization Toolbox (version 3.4 or later) and the Statistics and Machine Learning Toolbox.
NOTE that if you are running this cumputer lab on a mac you might experience unintended bugs or craches. If this occurs it is recomended to run the lab via a remote connection to the universities computer system. See below for how to set up a remote access the universities computers.
If you’re a student at Liu you can remove access the universities computer system via ThinLinc. See the link below for more information regarding this (note that page is in Swedish).
https://www.ida.liu.se/~TDIU08/UPP_Course_Mtrl/tools/thinlinc/index.sv.shtml
In the university's computer halls
If you are working on a Linux based computer in the computer hall, use the following steps to get MATLAB going.
First, open a terminal. Then run module add prog/matlab/2022a.
Note that the version sometimes changes, if 2022a can't be found, check available versions with module avail or module avail prog/matlab*. This should list all available modules or all available Matlab modules respectively.
Questions?
If you have questions when going through the lab, you can either bring them to the computer lab sessions. You can also raise them on the Q&A page on LISAM. In many situations, your fellow students probably know the answer to your question. Please help each other if possible!
Contents
- The biological system and experimental data
- Getting started
- Implementing Simple a Model
- Implementing the first hypothesis
- Implement the second hypothesis
- Quantitatively testing the hypotheses
- Testing the model with statistical tests
- Parameter Estimation - Improving the agreement to data
- Estimating model uncertainty
- Making predictions
- Experimental Validation
- Summary and final discussion
Main computer lab tasks
Have you read the introduction above?
The Biological system and experimental data
In this task, you will start to get familiar with the problem at hand, and will create functions that can plot the experimental data.
Read the background on the problem at hand
During the following exercises you will take on the role of a system biologist working in collaboration with an experimental group.
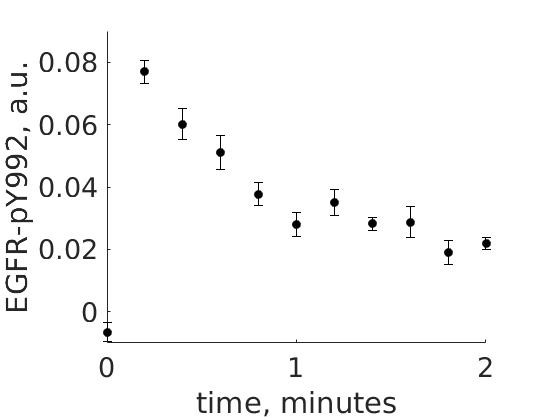
The experimental group is focusing on the cellular response to growth factors, like the epidermal growth factor (EGF), and their role in cancer. The group have a particular interest in the phosphorylation of the receptor tyrosine kinase EGFR in response to EGF and therefore perform an experiment to elucidate the role of EGFR. In the experiment, they stimulate a cancer cell line with EGFR and use an antibody to measure the tyrosine phosphorylation at site 992, which is known to be involved in downstream growth signalling. The data from these experiments show an interesting dynamic behaviour with a fast increase in phosphorylation followed by a decrease down to a steady state level which is higher than before stimulation (Figure 1).
Figure 1: The experimental data. A cancer cell line is stimulated with EGF at time point 0, and the response at EGFR-pY992 is measured
The experimental group does not know the underlying mechanisms that give rise to this dynamic behavior. However, they have two different ideas of possible mechanisms, which we will formulate as hypotheses below. The first idea is that there is a negative feedback transmitted from EGFR to a downstream signaling molecule that is involved in dephosphorylation of EGFR. The second idea is that a downstream signaling molecule is secreted to the surrounding medium and there catalyzes breakdown of EGF, which also would reduce the phosphorylation of EGFR. The experimental group would like to know if any of these ideas agree with their data, and if so, how to design experiments to find out which is the more likely idea.
To generalize this problem, we use the following notation:
EGF – Substrate (S)
EGFR – Receptor (R)
Getting started
How to set up the lab interface
The graphical user interface (GUI) version of the lab is available form here
- Unzip the downloaded file in an appropriate location.
To start the GUI you simply need to run the “GUILab.mlapp” file in MATLAB (version 2018b or later). There are three ways to do this.
If your computer recognises the .mlapp file format, you should be able to simply double click the file to run it in MATLAB.
Open MATLAB and navigate to the folder where you have extracted the files. Then either
- Type “GUILab” into the MATLAB command window.
- Drag the GUILab file from the folder on the left and drop it in the command window.NOTE! If you open simply double-click the GUILab.mlapp file in the MATLAB environment you will open the app development editor. Should this be the case, close this window and open as described above.
The first time you run the lab there will be a slightly longer start up time and there will be a lot of printout in the MATLAB command window. This is the main toolbox installing and is to be expected.
Implementing a Simple Model
To start with we will look at how we can define and simulate a very simple model.
Defining a model.
To start with run the “GUILab.mlapp” file in MATLAB to open the graphical user interface.
To define this model, press the “Define Model” button, this will bring up a secondary window that allows you to define your models. The components of this window are described below and depicted in figure 1.
The model text file – This is the primary text area and contains the .txt file that defines the model.
This drop-down menu contains previously saved models, which can be loaded into the primary text area with the “Load Model” button.
This text area displays relevant status text for a compiled or saved model.
This button compiles the .txt file into an executable MATLAB file, this is necessary for efficient model simulation.
This button saves the current content of the primary text area to be loadable at a later time. The model will be saved under the name defined under the heading “**********MODEL NAME”.
Figure 2 an overview of the Define model window.

Implementing the model.
We will start by defining and simulating a very simple model that describes a single state (A). The state A will have an initial value of 4 () and will increase at a constant rate of .
Bring up the Define model Window (as described above).
Define the simple model as depicted in the box below.
- Under the “**********MODEL NAME” heading, Give the model a suitable name.
- Under the “**********MODEL STATES” heading, define the derivatives (d/dt) of the model states. Followed by the initial condition of each state.
- Under the “**********MODEL PARAMETERS” heading, define the initial values of the model parameters.
- Under the “**********MODEL VARIABLES” heading, here we define what can be measured, also called the measurement equation or . In this model the measurement equation is equal to the amount of state A.
- Click the “Compile Model” button to compile and save the model.

Simulate your simple model.
Now you should simulate this simple model. Start by closing the define model window and return to the main GUI.
- Click the “Update List” button to update the list of models in the drop-down menu to include any new defined models.
- Select the simple model from the drop-down menu, the model will be listed under the name given during model definition.
- Press the “Simulate” button, this will simulate the model and plot the observed property as a blue line.
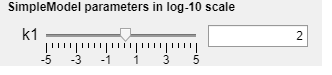
-The slider now labelled k1 can be used to change the parameter value of parameter , the model behaviour will change accordingly.
NOTE that the values on the slider are logarithms of 10 i.e. . The value in the text field is the actual parameter value.
Does the model behave as expected, given how you defined it? Please take a minute to consider the following questions before continuing.
- How is the initial value reflected in the plot?
- How is the parameter value , i.e. the rate of change in A, reflected in the plot?
If you are unsure regarding the answers to these questions, feel free to discuss them with another student or a supervisor.
Implementing the first hypothesis
Now that we know how to simulate a simple model, let us implement the hypotheses your collaborators have as models, and simulate them.
Read about the first hypothesis that your collaborators have
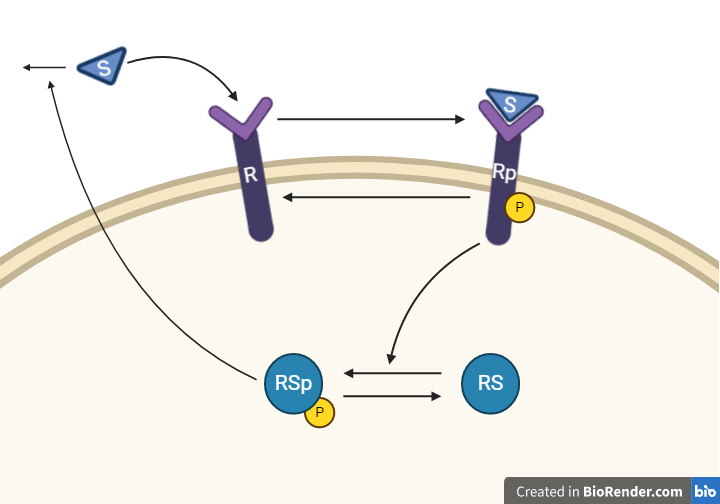
To go from the first idea to formulate a hypothesis, we include what we know from the biological system:
- A receptor () is phosphorylated () in response to a substrate ()
- A downstream signaling molecule () is activated as an effect of the phosphorylation of the receptor
- The active downstream signaling molecule () is involved in the >dephosphorylation of the receptor
- Phosphorylated/active molecules can return to inactive states without stimuli
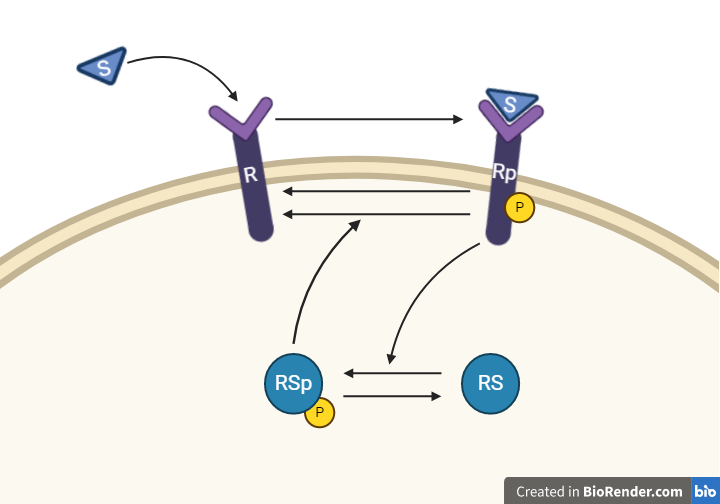
From this knowledge, we can draw an interaction graph as depicted in Figure 3, along with a description of the reactions.
Figure 3: Model 1 – The Feedback Hypothesis. The biological interpretation with the substrate the receptor and the signalling molecule (top). The model interaction graph of the states and the reactions with the corresponding parameters (bottom)
This model will consist of 5 states, 5 reactions with 5 kinetic rate parameters. All reactions are assumed to have mass action kinetics.
- Reaction 1 is the phosphorylation of the receptor (). It depends on the states and with parameter .
- Reaction 2 is the basal dephosphorylation of to . It depends on the state with the parameter .
- Reaction 3 is the feedback-induced dephosphorylation of to exerted by . This reaction depends on the states and with the parameter .
- Reaction 4 is the basal dephosphorylation of to . It depends on the state with the parameter .
- Reaction 5 is the phosphorylation of to . This phosphorylation is regulated by . The reaction depends on the states and , with the parameter .
The input to the model is the starting concentration of the substrate ().
Finally, the measurement equation is a one to one relationship with , it is defined by the variable .
Defining the model
Start by defining a model for this hypothesis, in the “define model” window. To help you get started you can use the template provided below. Note how “MODEL REACTIONS” can be used to simplify the expression of the state derivatives.
where and .
To complete the model in the box below, you will need to:
- Add a suitable model name.
- Complete the equations for states’ and
- Add derivatives for states’ , and .
- Add initial conditions for states’ , and .
- Define Reactions 3, 4 and 5 as described above.
- Add parameters , and .
- Define the measurement equation for , as described above.
Note that the derivatives of states and in the box to below are not complete and needs further additions to accurately correspond to the interaction graph in figure 3.
Use the following as initial values for the parameters and the model states.
Initial values Parameter values Once you are satisfied with the model use the “Compile Model” button to save and compile the model. Close the window and return to the Main GUI.

Simulate the first hypotheis
Use the “Updata List” button to update the drop-down menu.
- Select the model for the first hypothesis from the select model drop-down menu.
- Select the data file called “experimentalData.mat” from the select data drop-down menu. You can use the "Inspect Data" button to the left of the drop-down menu to get a better understanding of the data.
- Use the “Simulate” button to simulate the model for the first hypothesis.
- Save the plot of your simulation with the default parameters. Use the “Export Figure” button in the bottom right corner to export the current plot to a separate window. From this window you can save your figure.
In the main GUI you can now use the parameter sliders to change the corresponding parameter values to see how they affect the model simulation.
- Try to align the model simulation with the experimental data, using the parameter sliders to change the parameter values.
Implement the second hypothesis
Read about the second hypothesis that your collaborators have
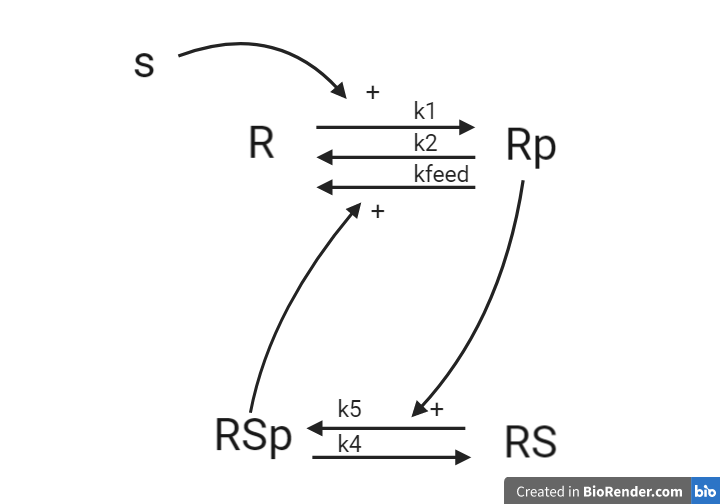
Let us now implement the second hypothesis. This hypothesis is similar to the first hypothesis and is depicted as an interaction graph in Figure 4. Study this interaction graph and note how it differs from the interaction graph in Figure 3.
Figure 4: Model 2– The Degradation Hypothesis. The biological interpretation of the second hypothesis with the substrate the receptor and the signalling molecule (top). The model interaction graph of the states and the reactions with the corresponding parameters (bottom)
This hypothesis is similar to the first one, but with some modifications. Here, the feedback-induced dephosphorylation of (reaction 3 in the first model) is removed. Instead we add a feedback-dependent breakdown of the substrate . This reaction is dependent on the states and with a parameter (same name, but a different mode of action).
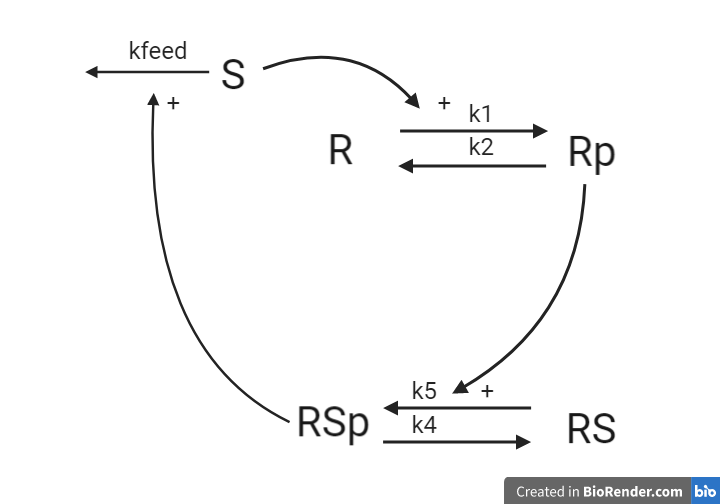
Define the model
To implement this second hypothesis as a model return to the Define Model Window. You can define this model by doing minor changes to your first model and saving it under a different name.
- Load your first model by selecting it in thedrop-down menu and clicking the “Load Model” button.
- Implement the changes necessary for the model to correspond to the hypothesis described above.
- Ensure that you select a different model name for your second model.
- Use the “Compile Model” button to save and compile your model for the second hypothesis.
Use the following as initial values for the parameters and the model states.
Initial values Parameter values
Simulate the second hypotheis
- Simulate your second model and save a plot of the simulation with the default parameter values.
- Try to align the model simulation with the experimental data, using the parameter sliders to change the parameter values.
Checkpoint 1: Show your supervisor the plots for both of your models with data, both for the initial parameter values given to you and your best estimation. Also present how you modified the first model to get the second model (show your equations).
Quantitatively testing the hypotheses
You will have noted by now that the agreement between simulation and data of
course is heavily dependent on the parameters. We will now start to address the issue of
obtaining parameters that yield a more agreeable fit. We will begin by looking at how we
quantify the difference between the simulated and the experimental data. If we have a value that describes how well our simulation, that depends on a set of parameter vlaues, agrees with the data, we can use this value to compare differnet sets of parameters. Lets call this value the “cost” of a given parameter set.
Read about the cost function
The cost is computed by the so-called cost function. The cost function is computed by taking the sum of the weighted residuals between the simulation and the experimental data points.
- The residuals are simply the differences be the data points () and the model simulation () i.e. .
- These residuals are weighted by the standard error of the mean (SEM) such that data points with large uncertainties contribute less to the cost function value.
The full cost function is formulated as
is the vector containing the parameter values.
is the cost of the parameters ,
is the time,
is the experimentally measured mean value at time point ,
is the model simulated value at time point , given parameters ,
is the standard error of the mean for the data at time point .The standard error of the mean essentially describes the uncertainty of a sampled mean value and is calculated as
Where is the sample standard deviation of the data at time point and is the number of observations at time point .
Try to find a good combination of parameter values
Since we want our model to give an accurate description of our experimental system, we want to find the parameters that minimizes the difference between our experimental data and our model simulation i.e. we want to find the parameters that minimizes the residuals. Since smaller residuals will result in a lower cost (), the parameters give the most accurate description of our experimental system will be the parameters with the lowest cost.
In the top right corner of the main GUI there is a tick box with the label "show residual", if ticked the plot will show the current residuals.
Next to the "Show residuals" box there is a second tick box, lablled "Show cost function value". When this box is ticked the GUI will display the cost function value for the current set of parameter values at the top of the window.
- Tick the “Show cost function value” box, in the upper right of the GUI.
To the left ot the "Show cost function value"-tick box there is a drop-down menu with the titel Select a cost function. If you hold the mouse pointer over the question mark to the left of Select a cost function it will display a tooltip with descriptions for different alternative cost functions.
Read through the descriptions for the different cost functions.
Select the cost function you think is most appropriate to use in this situation. If you are unsure, go through the "Read about the cost function" section above once more.
For both of your models, use the parameter sliders to try and find the set of parameters that results in the lowest cost.
- You can easily swap between your models via the select modeldrop-down menu.
Once you have a set you have a set of parameters with a satisfactory low cost use the “Save Parameters” button to save your parameters.
The “Save Parameters” button will save the current the parameters using the following naming convention
“ParameterValues_[MODEL NAME]cost([COST VALUE OF PARAMETERS])[DATE AND TIME].mat”A saved parameter sets can be loaded by selecting it from the drop-down menu and pressing the “Load” button.
Checkpoint 2: Give a short description of the different components of the cost function. Why do we square the residuals? Why do we normalize with the SEM? Present the plot of your best attempt to manually minimize the residuals/cost. When is the cost low enough?
Testing the model with statistical tests
Now that we have a way to quantitively asses the goodness of a models’ fit to data; it is time to determine if the model fit is good enough.
Read about statistical test to see if you must reject the model
There exist many statistical tests that can be used to reject hypotheses. One of the most common, and the one we will focus on in this lab is the chi-squared () -test. A -test is used to test the size of the residuals, i.e. the distance between model simulations and the mean of the measured data.
For normally distributed noise, the cost function, , can be used as test variable in the -test. Therefore, we test whether is larger than a certain threshold. This threshold is determined by the inverse of the cumulative -distribution function. In order to calculate the threshold, we need to decide significance level and degrees of freedom. A significance level of 5% (p=0.05) means a 5% risk of rejecting the hypothesis when it should not be rejected (i.e. a 5 % risk to reject the true model). The degrees of freedom is most often the number of terms being summed in the cost (i.e. the number of data points). In this lab we have 11 data points meaning that the inverse of a cumulative -distribution with a significance level of 5% equals
If the calculated cost is larger than the threshold, we must reject the hypothesis given the set of parameters used to simulate the model. However, there might be another parameter set that would give a lower cost for the same model structure. Therefore, to reject the hypothesis, we must search for the best possible parameter set before we use the -test.
- Given the -threshold of 19.68 and the best model fit you acquired earlier, can you reject either of the two hypotheses?
- Can you be certain that there exists no set of parameters that would generate a lower cost?
Parameter Estimation - Improving the agreement to data
To be able to truly test a hypothesis, we must find the parameters that yield best possible agreement between data and simulation.
Read about parameter estimation
If the model is not good enough assuming we have the best possible parameters, the hypothesis must be rejected. It is possible to find this best combination of parameters by manually tuning the parameters. However, as you might have discovered this is difficult and could take along time. Instead, we can find the parameters that yield the best agreement using optimization methods.
An optimization problem generally consists of two parts, an objective function with which a current solution is evaluated and some constraints that define what is considered an acceptable solution. In our case, we can use our cost function as an objective function and set lower and upper bounds (/) on the parameter values as constraints. The problem formulation typically looks something like the equations below.
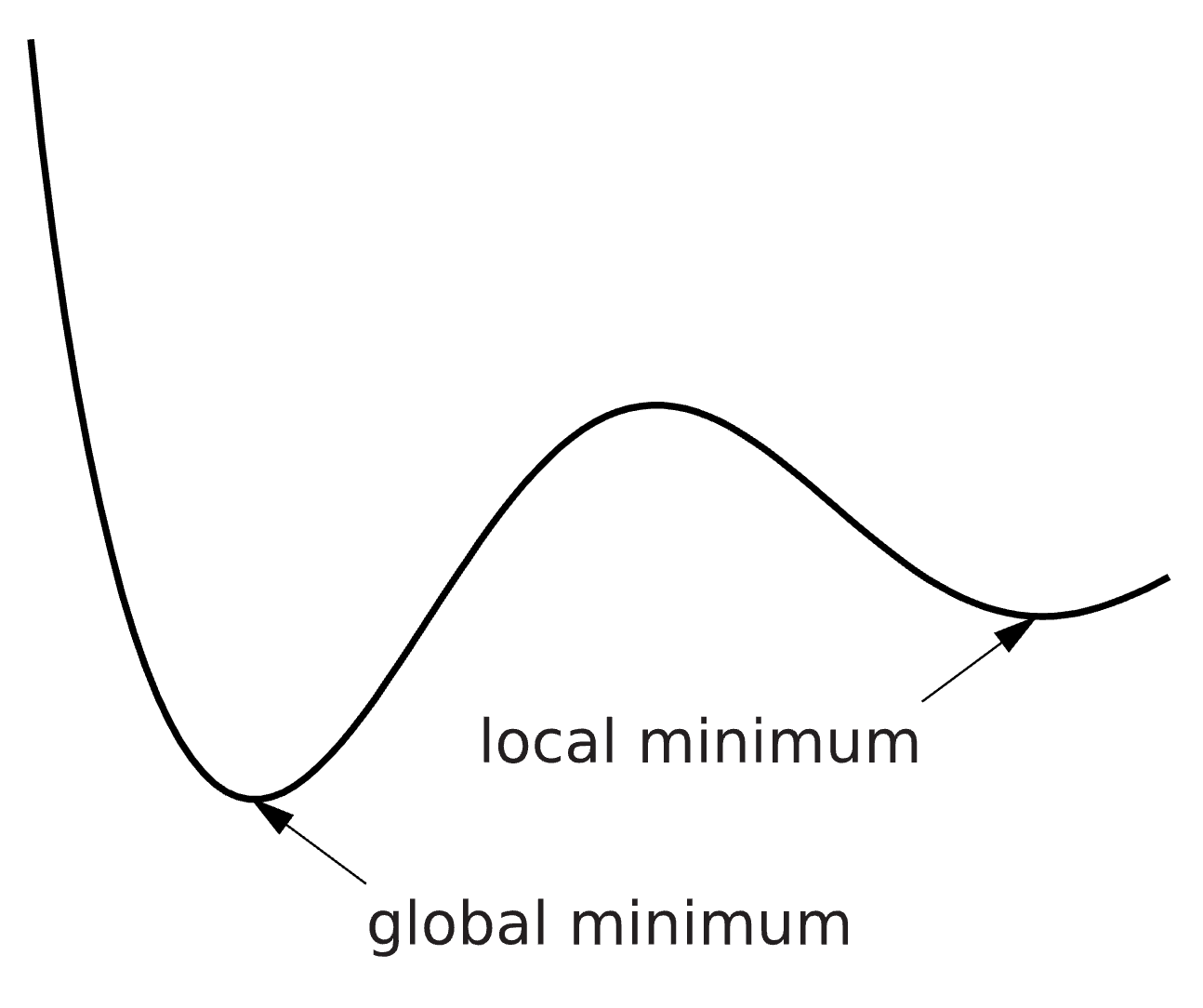
where is the optimal set of parameters that minimizes the cost function . An optimization problem can be hard to solve, and the solution we find is therefore not guaranteed to be the best possible solution. We can for example find a solution which is minimal in a limited surrounding, a so-called local minimum, instead of the best possible solution – the global minimum. There are methods to try to reach the global minimum, for example you can run the optimization several times from different starting points and look for the lowest solution among all runs. Please note that there might be multiple solutions with equal cost values.
Figure 5: An Illustration of the objective function landscape that is explored during optimization. With the difference between local and global minimum illustrated. .
Run a parameter estimation for both of your models
In the main GUI you can use the “Optimize Parameters” button to run an implemented optimization algorithm for the currently selected model and experimental data. The optimization algorithm will search for a set of parameter values that minimizes the currently selected cost function, starting with the currenly set prameter values. Note that the optimization process will take several minutes to complete. Once completed the optimal parameters will be presented on the parameter sliders and the plot will update to plot the optimal solution.
- For each model, click the “Optimize Parameters” button to initiate the optimization algorithm. The optimization will take about two minutes to complete (might be faster).
Note also that there is no guarantee that the optimization algorithm will return the same value every time it is run. Running it again might return an even better parameter set with a better cost value. Further, the optimization algorithm will use the current parameter values as an initial guess i.e. subsequent optimizations is more likely to result in better solutions.
- To ensure that we find the best possible solution, run multiple optimizations for both models.
- Remember that you can use the “Save Parameters” button to save a found parameter set before running a new optimization.
- For each model, save the plot of the best solution you found, using the “Export Figure” button.
Checkpoint 3: Which models has the best fit to the data in terms of lowest cost? Could either model be rejected? Plot the optimal fits of both model to the experimental data and show your results to your supervisor.
Estimating model uncertainty
Now that we know whether our models should be rejected or not, given the solution from our optimization algorithm, it is time to estimate the uncertainty of our models.
Read about how we can estimate the model uncertainty
After the optimization procedure, we decide if the hypothesis should be rejected or not. If the best cost value is lower value than the -threshold, we will move on and further study the behaviour of the model. Unless the best solution is strictly at the boundary, there exists worse solutions i.e. solutions with a higher cost, which would still be able to pass the statistical test. We will now look at all these acceptable solutions. In this analysis, we study all found parameter sets that has a cost lower than the -threshold i.e. all parameter sets that give an acceptable agreement between model simulation and experimental data. These parameter sets are used to simulate the uncertainty of the hypothesis given available data. This uncertainty can tell us things like: Do we have enough experimental data in relation to the complexity of the hypothesis? Are there well determined predictions (i.e. core predictions) to be found when we use the model to simulate new potential experiments?
Since we know the -threshold for our experimental setup, each time we evaluate a parameter set we can also check if the cost for that parameter set is lower than the -threshold. If it is, we simply save that parameter set.
please note that this is not a completely reliable estimation of the model uncertainty but rather a minimal estimation of the model uncertainty. A true uncertainty estimation is a much larger and more time-consuming analysis. Hence, in this introductory computer exercise this underestimated model uncertainty will be considered good enough.
Estimate the uncertainty for your models.
In this lab the modle uncertainty will be estimated form a set of acceptable parameter values. During the optimization process the GUI has automatically saved the acceptable sets of parameters that was encountered. However, this results in a very long list of acceptable parameter values. Therefore, you will need to sample a subset of acceptable parameter values to estemate the model uncertainty.
In the botom left corner of the GUI there is a drop-down menu that allows you to select between different sampling approaches. If you hold the mouse pointer over the question mark, the tooltip will describe the differnet approaches. You can also set the number of sampels that will be drawn by your selected approach in the box to the right of the drop-down menu.
- Select a suitable sampling approach from the drop-down menu.
- Set a suitable number of samples to use for you uncertainty estiamtion.
You can now use the “Plot Model Uncertainty” button at the bottom of the GUI simulate and plots the simulations for the sampled parameter sets, giving you the model uncertainty.
The estimated model uncertainty is really a cmbantion of many differnet simulations, and each simulation can be plotted as a seperate line. However, as you might notice such a plot can be quite messy, one alternative is to combine all of these lines into a shaded area that represents the total uncertainty. You can use the tick box ate the bottom of the GUI to plot the uncertainty as a sahded area
For each model respectively
- Use the “Plot Model Uncertainty” button at the bottom of the GUI to plot your model uncertainty. Note that this might take some time to complete, depending on the number of samples used.
- Experiment with differnt combinations of sampling approaches and Number of Samples to see how they affect the estimated uncertainy. You can always save your plots for comparrison with the Export Figure button, at the bottom right of the GUI.
- Once you have tried a few sampling approaches and number of samples, and you have found a combination that you feelgives a good estimation of the model uncertainty. Click the Save model uncertianty button. This saves the sampled parameter sets to be used later.
A few kown bugs.
- If the "Plot Model Uncertainty" button is used with the "Show residuals" box ticked it will cause an "Dimensions of arrays being concatenated are not consistent."-error. Solution: Untick the "Show residuals" box and click the "Plot Model Uncertainty" again.
- If the "Plot Model Uncertainty" button is used without having found an acceptable in the preceding optimization it will cause an "Empty format character vector ..."-error. Solution: Run additional otpimizations and click the "Plot Model Uncertainty" again.
- Use the “Save Model uncertainty” button to save the estimated uncertainty. This is required for a later step of this lab.
- The Uncertainty will be saved with the following naming convention
SampledParameters_[MODEL NAME]_[DATE AND TIME].mat
Note the file name of your saved model uncertainty as you will need to select it later.
- Save your plot with the model uncertainity, using the “Export Figure” button
Checkpoint 4: Show your plots with the uncertainty of the models to the supervisor. Are the uncertainties reliable? If not, are they too big or too small?
Making predictions
Now that we have an estimation of the model uncertainty, it is time to make predictions of new experiments. A good model cannot only explain estimation data, it can be used to generate good predictions for new set of circumstances .
Read about predictions
In order to see if the model is behaving reasonably, we want to see if we can predict something that the model has not been trained on, and then test the prediction with a new experiment. Note that for the prediction to be testable, it must be limited in at least one point, often referred to as a core prediction. A core prediction could for example be found at one of the model states where we do not have experimental data, or at the model state we can measure, under new experimental conditions (extended time, a change in input strength etc.).
Core predictions are well determined predictions that can be used to differentiate between two models. Such a differentiation is possible when model simulations behave differently and have low uncertainty for both models. Core predictions are used to find experiments that would differentiate between the suggested hypotheses and therefore, if measured, would reject at least one of the suggested hypotheses. The outcome could also be that all hypotheses are rejected, if none of the simulations agree with the new experiment.
Use your models to predict the outcome of a new experiment
In this lab we will use our models predict what happens if we introduce additional substrate () to the system at a second timepoint. The current interpretation for both of your models is that substrate is only introduced at the start of the experiment, , i.e. .
To model the introduction of additional substrate you will need to modify your model
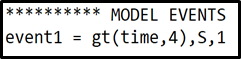
definitions. You will need to introduce something called events, which causes something to happen once a given condition is fulfilled. The something we want to happen is that new substrate is added i.e. our state is set to be equal to . The condition for this should be that the time is equal some given time point e.g.The above described event would be implemented in your model file like this:
where is the name of the event, states that we want the event to trigger at time , defines that we want to change the value of state , and the at the end defines that we want to change the value of state to one. Note that the event is implemented under the “***********MODEL EVENTS” heading.
- Open the model definition window with the “Define Model” button.
- Load your model by selecting it from the drop-down menu and clicking the “Load Model” button.
- Add an event that introduces new substrate as described above.
- You are free to choose the time point of the new substrate, the in the example above is selected for demonstration purposes.
- Use the “Compile Model” button to save and compile your modifications.
- Repeat the above steps for your second model.
Note that it is important that the event is identical for both models since we want to compare them, and a comparison is only meaningful given identical conditions.
- Return to the main GUI and click the "Model predictions” tab in the top right of the window, to sawp to the Predictions window
In the prediction window
- Select your first model and the file with the corresponding estimated parameter uncertainty that you saved before, from the respective drop-down menus.
- Select your second model and the file with the corresponding estimated parameter uncertainty that you saved before, from the respective drop-down menus.
- Enter a suitable time length of the simulation, if you choose to add substrate at e.g. then a suitable time length of simulation could be 6 s. this ensures that your simulation encompasses the response to the new substrate.
- Click the “Simulate Predictions” button to simulate your predictions. Note that the time to simualte the models will again depend on the number of sampled parameter sets used in the saved files.
Make sure that you have selected the correct parameter files for your respective models.
- Can you identify a core prediction that can be used to distingush between the two hypotheses?
- Would you suggest that this experiment, i.e. adding substrate at a second time point, is performed?
Checkpoint 5: Show a supervisor your figure with the predictions. Could you find a core prediction? What is a core prediction and why is it important? Would you suggest that this experiment performed?
Experimental validation
Read about how we can use experimental validaion
The last step of the hypothesis testing is to hand over your analysis to the experimental group. Any core predictions that discriminate between Model 1 and Model 2 should be discussed to see if the corresponding experiment is possible to perform. Now it is important to go back to think about the underlying biology again. What is the biological meaning of your core predictions? Do you think the experiment you suggest can be performed?
Once we have established that the experiment we predicted can be performed and is of value the experimental collaborators will do so and collect new experimental data. This data can be used to validate our models or to discriminate between two competing models.
Experimental validaion
In this exercise you can use the “Generate new data” button in the Prediction window to acquire this validation data. But first you will need to define at which time point you choose to add additional substrate. It is important that this time point correspond to the timepoint you choose when defining the events for your predictions.
Enter the time point at which additional substrate is added.
Click the “Generate new data” button to generate data from the new experiment.
Save your figure with both your predictions and the new data, using the “Export Figure” button.
- What would you conclude by comparing the simulations of your hypotheses to the validation data?
Checkpoint 6: Show a supervisor your figure with the predictions and the new data. Can you reject any of the hypotheses?
Summary and final discussion
To concludes this computer exercise, we will look back upon what you have done. Below are some questions to discuss with the supervisor. These questions are all points that have been covered in this lab, if you are unsure about any of the answers go back and look through the corresponding section .
Some summarizing questions to discuss
You should know the answers to these questions, but if you do not remember the answer, see this part as a good repetition for the coming dugga.
- Look back at the lab and, can you give a quick recap of what you did?
- Why did we square the residuals? And why did we normalize with the SEM?
- Why is it important that we find the "best" parameter sets when testing the hypothesis? Do we always have to find the best?
- Can we expect to always find the best solution for our type of problems?
- What are the problems with underestimating the model uncertainty?
- If the uncertainty is very big, how could you go about to reduce it?
- Why do we want to find core predictions when comparing one or more models? What would be the outcome if one did the experiment?
Checkpoint 7: Discuss the questions above with a supervisor. Think if you have any additional questions regarding the lab or Systems biology and feel free to discuss this with a supervisor